Invitation to dance: a status report on the Ballet project
Posted on Tue 30 June 2020 in research
At MIT, we recently marked the close of one of the most turbulent academic years on record, in which academic and research activities were significantly disrupted by the emergence of the COVID-19 pandemic, which has by now, killed well over 400,000 people globally and 100,000 people in the US. As neighbors and loved ones got sick, we all asked ourselves the question, "what can I do to help?" For many of my colleagues at MIT, this meant accelerating engineering and design work on personal protective equipment and medical devices or contact tracing apps or vaccines and therapeutics.
The expertise of many others did not lend itself to these direct responses. Instead, a swarm of academic and independent data scientists took to putting their skills to use to try to predict the trajectory of new infections, identify positive cases from chest X-rays, generate heat maps from foot traffic data or satellite imagery, or aggregate signs of pre-symptomatic individuals — with varying degrees of success and statistical rigor.
Tweet of masonporter/1273054551583555585
What happens when hundreds or thousands of people try to collaborate on similar data science projects at once? Many amazing projects do emerge, especially in terms of the curation of high-quality datasets and exploratory analyses. However, as we found here — and as we have found in similar prior situations em — there is also a lot of noise. For example, in one blog post that went viral, a data scientist claimed to detect COVID-19 cases from chest X-ray imagery with close to 100% accuracy, an absurd claim that actually amounted to adapting a common pre-trained Resnet model and fine tuning on a dataset of only 50 images.
I've been following these efforts closely, especially because I've been thinking about some of these exact same issues as part of my PhD research for several years now. The project I've been working on is Ballet, a software framework for collaborative data science. I'm taking this moment to provide a status report on the project. This status report will be most useful to data scientists interested in collaborating more effectively, but will also be interesting for anyone wanting to learn more about this work.
Introduction to Ballet
While the open-source model for software development has led to successful, large-scale collaborations in most software projects, it has not been nearly as successful in data science and in particular, predictive/supervised machine learning.1 By this, I mean projects where the output of the project is not a software library but a trained model capable of serving predictions for new data instances. These models are rarely developed in open-source, and when they are, they rarely have more than a handful of collaborators.
There is great potential impact of large-scale, collaborative data science to address societal problems through community-driven analysis of public datasets. I think that we have come nowhere close to the potential of this approach. Here are some examples of how collaborative data science could have an impact:
-
In the time of COVID, many data scientists could join together to build an open-source predictive model for new cases in different geographies or easily extend a model to cover their own location, complementing legacy models produced by independent research groups and government agencies.
-
The Fragile Families Challenge tasks researchers and data scientists with predicting outcomes like GPA and eviction for a set of disadvantaged children, with the goal to yield insights to improve the lives of disadvantaged children in the US. To build a model for the Fragile Families Survey dataset requires trying to understand the 208,000 line codebook. Other similar survey datasets also contain key insights for social science researchers but have a huge cost in terms of preparing data for analysis and designing features for causal inference or predictive modeling.
-
The crash-model project is an application to predict car crashes and thereby direct safety interventions to the most dangerous intersections and road segments.
Collaborative and open-source development gives us the opportunity to move the successes of machine learning beyond predicting click-through rate, recommending engaging content, and recognizing faces, and closer to applications that positively impact the way people live their lives.
The table below shows the number of unique contributors to different projects in software engineering and in data science. These are the projects that I have catalogued as the largest open-source collaborations.2 I am always struck by the three orders of magnitude difference across project types. While there are many reasons for this disparity, I'd like to briefly touch on two of them.
| Software engineering | Data science | ||
|---|---|---|---|
| Linux kernel | 20,000+ | drug-spending | 20 |
| Ruby on Rails | 3,900+ | police-eis | 19 |
| kubernetes | 2,400+ | crash-model | 18 |
| tensorflow | 2,400+ | food-inspections | 8 |
Modularity
The first is that it is difficult to decompose data science pipelines into small modular patches. Unlike software engineering, where a patch can be applied to introduce a new software feature or fix a bug, its less apparent how to "patch" a data science pipeline to improve its performance. This is especially challenging as many parts of the data science process are usually implemented in end-to-end scripts. Without the ability to apply modular patches, it is difficult or impossible to use version control tools to collaborative on a single project.
Development workflow
The second is that data scientists are accustomed to working in computational notebooks and have varying mastery of version control tools like git. Unfortunately, notebook-based development workflows don't fit in to traditional software engineering workflows. I love Jupyter Notebooks, and use them all of the time in my work, but many writers have pointed out their drawbacks: difficulty managing code, sharing code and receiving feedback, replicating results, cleaning up "messes", productionizing models and analyses. The telltale sign of this mismatch in a project is a directory named something like notebooks/ containing notebooks each authored by a single person. How can workflows be adapted to use a shared codebase and build a single product?
Towards a solution
To address these challenges, I've been working on a new way to facilitate collaboration in data science projects.
The first part of the approach is based on finding ways to decompose the data science process into modular patches — standalone units of contribution — that can be intelligently combined, representing objects like "feature", "labeling function", or "prediction task definition". Prospective contributors work in parallel to write patches and submit them to an open-source repo where our framework provides functionality to identify and merge high-quality contributions and compose the accepted patches into a single product.
The second part of the approach is meeting data scientists where they are — the notebook — as the primary IDE. After prototyping a new feature, say, within a notebook, using our interface a data scientist can transparently submit the code that defines that feature as a pull request (PR) to the upstream project repo without bothering themselves with any git details.
We instantiate these ideas in Ballet, a software framework for collaborative data science. It initially supports collaborative feature engineering on tabular data, which will be the focus of this post. But keep in mind that this is one instance of the ideas behind Ballet, and that they apply equally to other areas of data science, with a plugin to support data programming for document classification in development.
In the rest of this post I will go through many of these ideas in an end-to-end example of collaborating on a house price prediction problem. Throughout this example I will be focusing on feature engineering where each patch to the project is a new feature definition.
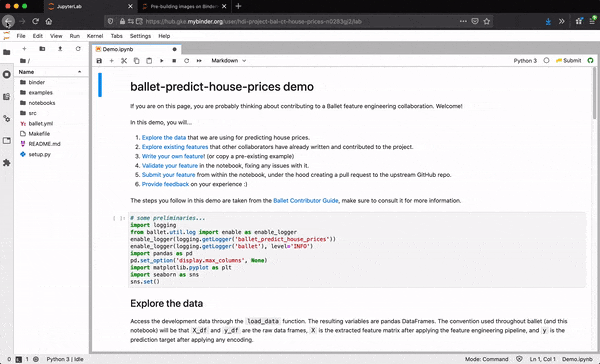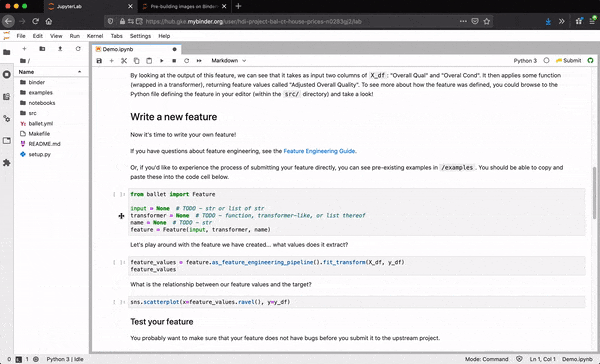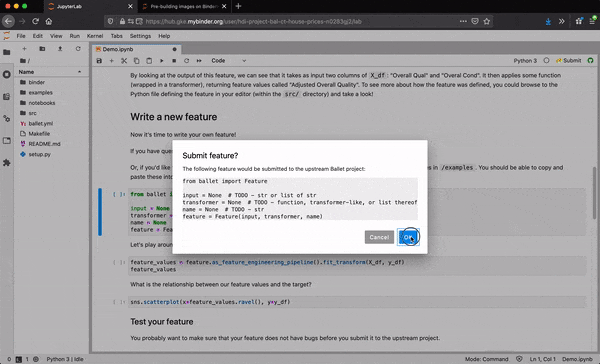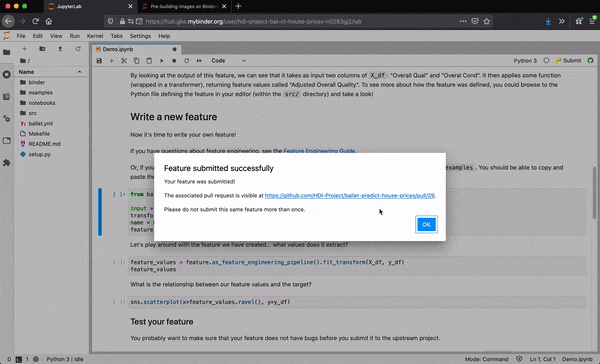
Collaborating on feature engineering for house price prediction
Let's take a closer look at these ideas through the case of a collaboration on feature engineering for house price prediction. Here the data is raw characteristics of houses and their selling prices in Ames, IA. This messy, real-world dataset requires significant feature engineering by experts before a usable feature matrix can be input to a learning algorithm.
Completed feature engineering pipeline
Let's first imagine for the purpose of induction that the project is already underway. What is the product that is being made available to the data science community? It is an end-to-end feature engineering pipeline that can be fit on existing house price data and used to extract feature values from unseen house records. The project can be pip-installed by a totally different set of developers, and the feature engineering pipeline can then be inserted into some other ML pipeline.
from ballet_predict_house_prices.load_data import load_data
X_df_tr, y_df_tr = load_data(input_dir='./data/train')
X_df_te, _ = load_data(input_dir='./data/test')
from ballet_predict_house_prices.features import build
mapper = build(X_df_tr, y_df_tr).mapper_X
mapper.transform(X_df_te)
What is notable about this already is that the feature engineering pipeline itself is exposed as a "mapper" object that provides a fit/transform API. This means that developers can create the pipeline and learn parameters from a training data set, while others can install the pipeline and extract features for their own data. In contrast, in many modeling efforts features are extracted in a single end-to-end script which relies on data already being split into train and test sets and often leaks information from the test set to the feature engineering, such as column means for imputation or knowledge about column skew in the test set.
One feature at a time
Well that's great. We have a robust feature engineering pipeline that can be fit on training data and applied on unseen data instances to extract feature values. Our downstream collaborators can use this as a key input to their modeling process. But how did we build this pipeline in the first place?
The key here is the insight that feature engineering can be represented as a dataflow graph over individual features. We structure code that extracts a group of feature values as an individual patch, calling these logical features. Individual features are represented as individual Python modules, stored in the git source, and "collected" dynamically by the Ballet framework.
As one plugin for Ballet, we create a small embedded language for feature engineering. Users are responsible for declaring one or more input columns to their feature and one or more sklearn-style transformers that sequentially operate on these columns. We supplement the many high-quality transformers available in sklearn and elsewhere with feature engineering primitives. This makes it easier to rewrite imperative Pandas code to be modular and robust to unseen data.
Here's how it looks. The user has requested the Lot Area variable from the raw dataset, which contains noisy measurements of each house's lot area. They propose to first conditionally unskew this variable by taking the log of the lot area if the skew on the training data is greater than some threshold (here at 0.75). Then any houses that have missing lot areas are imputed with the mean of the training lot area. (If the imputation were done first, the level of skew in the training data would be artificially less as new observations would be added at the mean.)
from ballet import Feature
from ballet.eng import ConditionalTransformer
import numpy as np
from sklearn.impute import SimpleImputer
input = 'Lot Area'
transformer = [
ConditionalTransformer(
lambda ser: ser.skew() > 0.75,
lambda ser: np.log1p(ser)),
SimpleImputer(strategy='mean'),
]
name = 'Lot area unskewed'
feature = Feature(input=input, transformer=transformer, name=name)
Feature objects can then be composed as part of a FeatureEngineeringPipeline, which in turn provides a transformer API:
from ballet.pipeline import FeatureEngineeringPipeline
pipeline = FeatureEngineeringPipeline([feature1, feature2, feature3])
pipeline.fit_transform(X_df)
The pipeline extracts feature values more or less as follows (replacing fit_transform with just transform after training). Under the hood we use a DataFrameMapper from the sklearn_pandas project. This is similar to the functionality provided by sklearn's recent ColumnTransformer, to which we may migrate if sklearn reaches feature parity.
# pseudocode
for feature in features:
x = X_df[input]
for transformer in feature.transformer:
x = transformer.fit_transform(x)
yield x
The Ballet Feature Engineering Guide provides a more full discussion.
So a feature engineering pipeline is composed of many individual features. These features are developed independently and in parallel by contributors to the project. Remember, the same ideas apply to other parts of the data science process in addition to feature engineering, but feature engineering is the focus of the ballet-predict-house-prices project and is supported by the plugin that I've just described.
Experiment and develop
A development workflow that requires data scientists to clone a repo, set up a virtualenv, work on a new branch, write and run unit tests, and push code to be reviewed, is a relatively high burden compared to their desire to experiment and develop in a notebook environment. To support setting up a development environment, we pair every Ballet project with a Jupyter Lab environment that can be easily built from the repository contents, leveraging Binder to run Lab in the cloud.
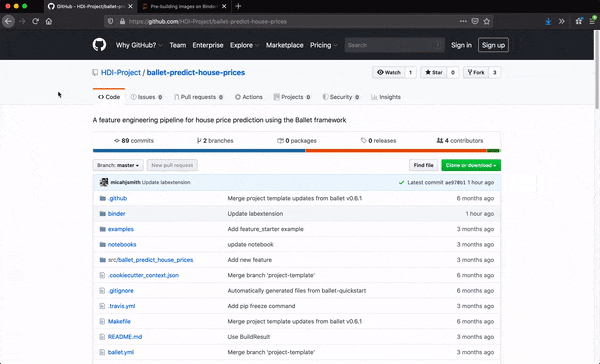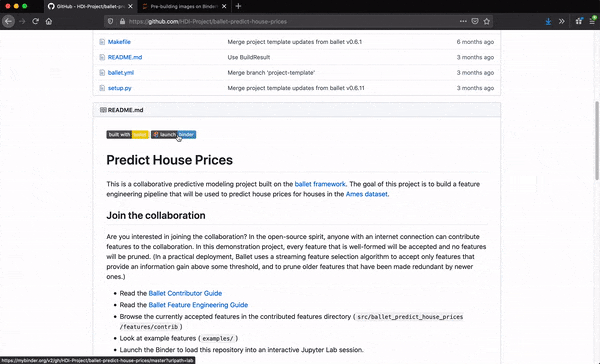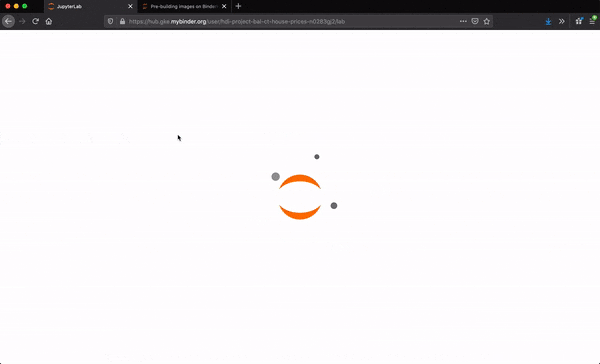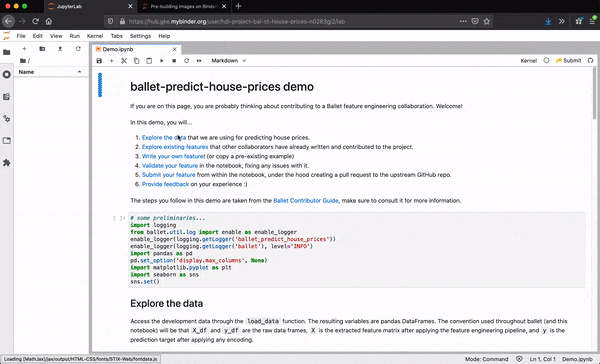
Each Ballet project, like ballet-predict-house-prices can be rendered from a provided template using the ballet quickstart CLI. The resulting repo is pre-configured for launch within Binder with a Ballet-specific Jupyter Lab extension installed.
Validate, validate, validate
Suppose that a prospective contributor has developed the Lot area unskewed feature shown above and wants to contribute it to the upstream project. Just as in a typical software project, new code contributions must be thoroughly evaluated for quality before being accepted. What does that mean for evaluating quality of logical features? Here, Ballet identifies analogues for unit testing and integration testing: feature testing and streaming logical feature selection.
Feature testing broadly ensures that the user-contributed feature provides the proper API and successfully deals with common error situations, such as intermediate computations producing missing or non-numeric values.
Streaming logical feature selection evaluates feature contributions in terms of their impact on machine learning performance as they arrive to the project repo. Does the feature engineering pipeline have better predictive performance with or without the proposed feature? Performance can be measured in several ways and the outcome must be estimated statistically.
If the feature fails any of these tests, it will be rejected and will not become a part of the composite feature engineering pipeline. This ensures that at all points, the pipeline can be used by downstream collaborators as part of their modeling process and patching it always improves the performance of the end-to-end model.
In a Ballet development workflow, these tests happen twice.
First, features can be tested locally, within the notebook, using an API exposed by the Ballet library. Any failures are reported with suggestions for addressing them.
from ballet.validation.feature_api import validate_feature_api
validate_feature_api(feature, X_df, y_df)
# True
from ballet.validation.feature_acceptance import validate_feature_acceptance
validate_feature_acceptance(feature, X_df, y_df)
# True
The second time is when feature submissions have been received by the upstream project, discussed below.
Submit where you code
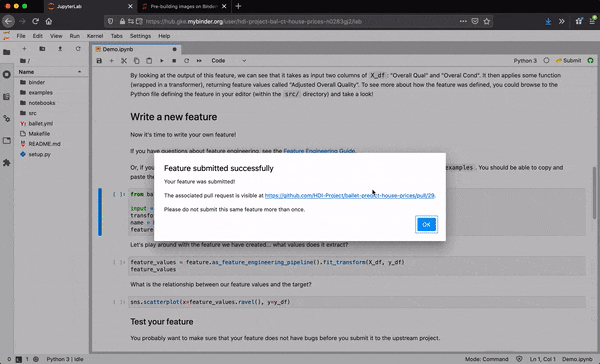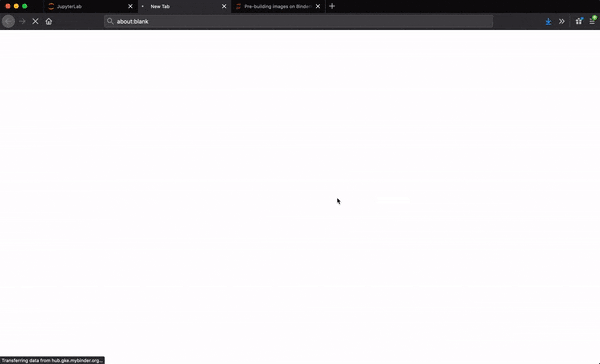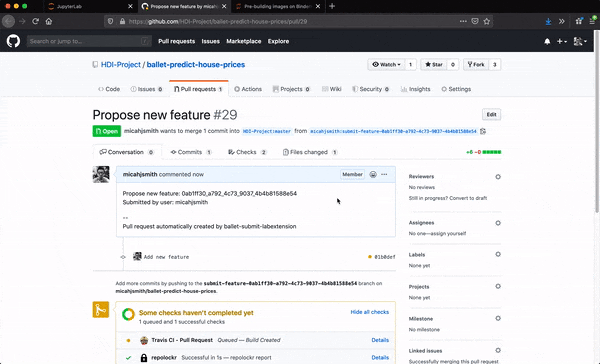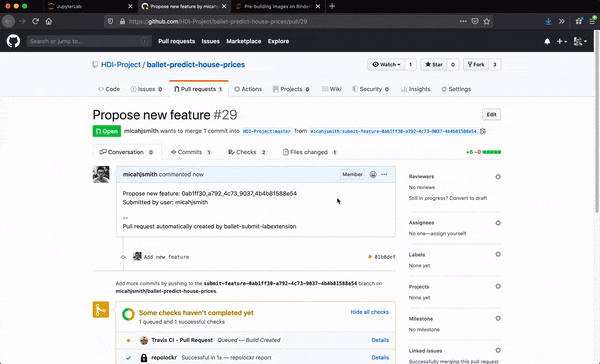
To support contributing code to be reviewed, we create a Jupyter Lab extension to submit patches of data science code to the upstream repository directly within the Lab interface and transparently to the user. Data scientists can select the code that defines the new feature they want to submit and submit it from Jupyter Lab with one click.
First, they can authenticate themselves with GitHub. This allows the Lab extension to take actions on their behalf, avoiding the need for the data scientist to run any low-level git commands themselves.
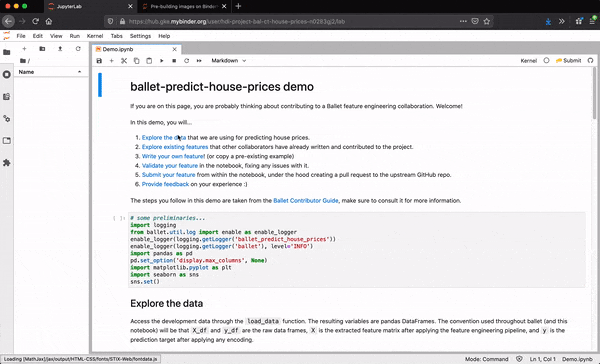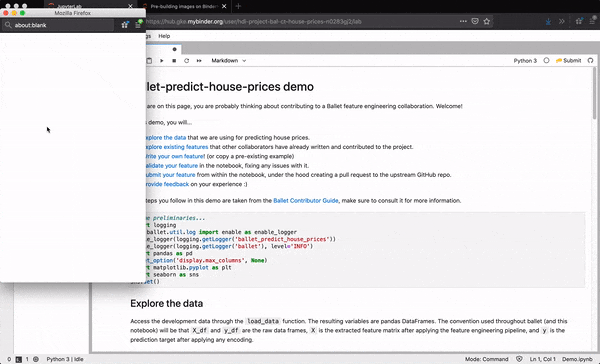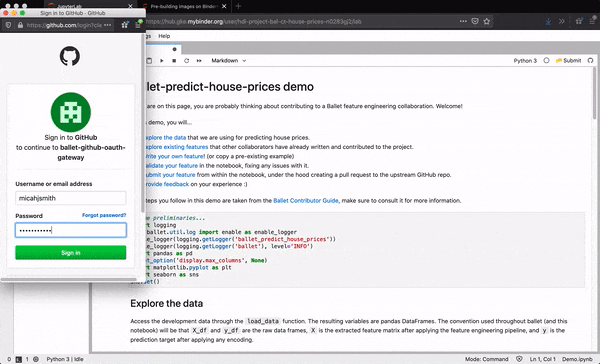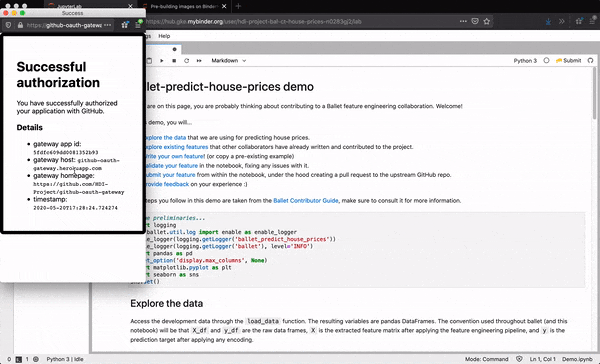
Under the hood, the extension forks the repo on behalf of the user, creates a new Python module at the expected path within the package, populates the module with the desired source code, commits the changes, pushes the results to the fork, and creates a new PR to the upstream repo.
The end result is that data scientists develop entirely within the notebook without having to switch tools or refactor their code when they want to "productionize" it. They can even view the PR that was created on their behalf if they want.
Automate as much as possible
As the project begins to receive submissions of new logical features from contributors, project maintainers have the burden of validating the proposed features and responding to PRs. As the number of collaborators and features scales up, this burden can become prohibitive to sustainably maintaining an open-source project. It can be especially difficult because just reading the code in a PR may not be enough for a human to validate data science code — a quantitative evaluation is necessary in most cases to ensure the feature values improve the performance of the pipeline.
The way to support maintainers and ensure the sustainability of the project is to automate as much of project maintenance as possible.
When a new PR is opened, an extended version of the validation tests described above are run by a continuous integration service provider, like Travis CI. In addition to feature testing and streaming logical feature selection, the CI tests also ensure that the PR places the new module at the correct path in the project.
Here we can see that on a PR to the ballet-predict-house-prices project, there are four jobs that are run.
-
The project structure validation job passed, indicating that the user has placed their feature at the correct path within the project (here within
src/ballet_predict_house_prices/features/contrib) and named their subpackage and module appropriately. -
The feature API validation job failed, indicating that the feature failed to successfully extract feature values for unseen data. There's not much to dig into here, as this example shows a degenerate feature where no transformer was provided. In other situations, the PR submitter can look into the Travis CI logs to see a detailed accounting of the failures of their feature with opportunities to improve it.
-
The feature acceptance evaluation failed, indicating that the feature (which already was degenerate anyway) failed to improve the performance of the existing feature engineering pipeline. This is one phase of the streaming logical feature selection algorithm used by this Ballet project, the second of which is the pruning evaluation to follow.
-
The feature pruning evaluation succeeded, which isn't super interesting here – the pruning phase of the feature selection algorithm runs only when a feature has been merged to the master branch to determine if it has made any existing features redundant. Here the pruning phase was skipped since it was not run from the master branch and the job succeeded as a result.
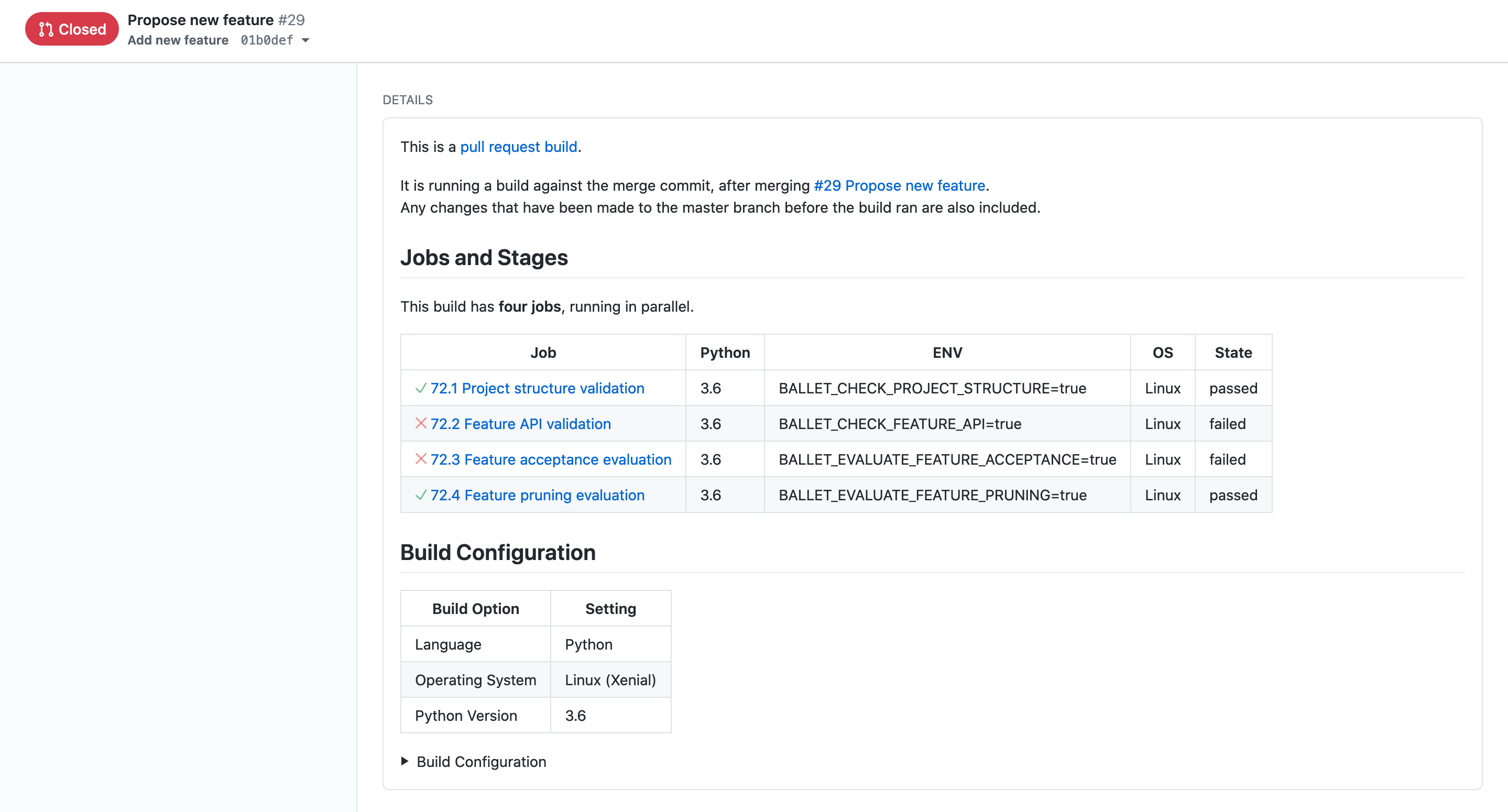
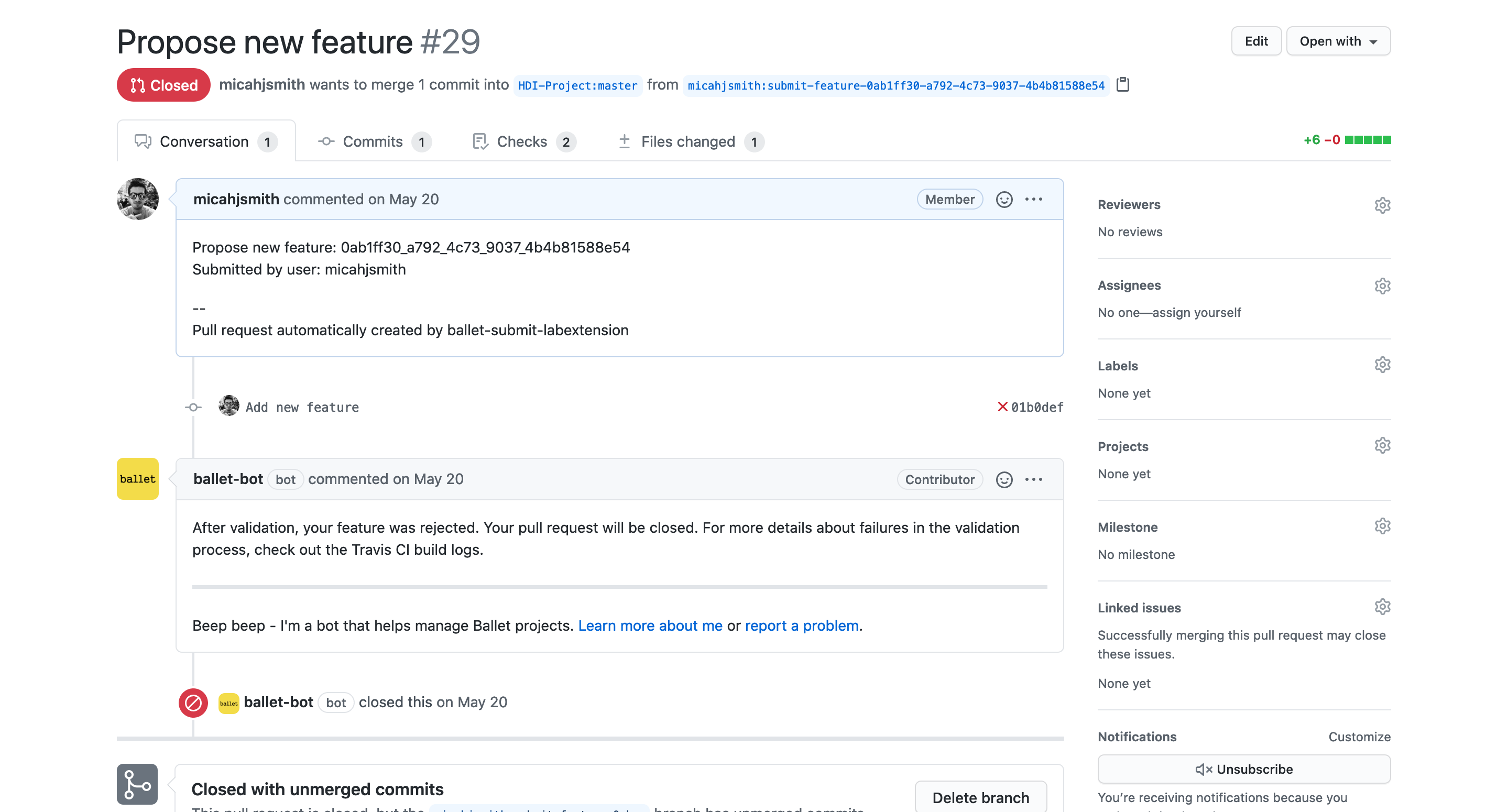
Depending on the CI job results, the maintainer can reasonably expect to either merge or close the PR without any additional changes or discussion required. By default, Ballet supports automatically closing PRs that fail their tests using the "Ballet Bot" that can be installed for free on any Ballet project. Maintainers can even enable Ballet Bot to automatically merge PRs that pass their tests, but this is not enabled by default, because it is feasible that a contributor's code might still introduce errors/bugs into the pipeline.
Here we can see the actions taken by the Ballet Bot in response to the failing jobs. The bot closes the PR automatically and explains why it has done so to the user. They have the option of trying to fix the problems with their feature and submitting it again, or moving on to a new idea.
An invitation
Interested by these ideas? The ballet-predict-house-prices project welcomes new collaborators. Use the Lab interface running on Binder to explore the data and the existing feature engineering pipeline and develop a new feature. Contribute your new feature and have your name added to the list of committers to the project! If you'd like, you can then leave feedback or fill out our survey about your experiences. To begin, click the link below to launch the project on Binder:
![]()
You can also use Ballet to set up your own collaboration or get in touch with me directly.
Further reading
- Ask me for a preprint of the full-length paper on Ballet.
- Read about the Ballet framework.
- Check out my account of MLSys 2020 where I presented a live demo of Ballet or read the short paper about my demo.
- Join a collaboration in feature engineering for house price prediction.
-
In predictive ML projects, the output of the project is not a software library, but rather a trained model capable of serving predictions for new datapoints. ↩
-
As of February 2020. Of course, let me know if you think there are other projects that should belong on this list. I measure the number of unique committers to open-source projects. For data science projects, the project must produce as its ultimate output a single model/pipeline that can be trained end-to-end and serve predictions for new data instances. If it produces additional outputs, such as maps, web services, notebooks, or reports, that is a bonus, but not relevant to my analysis here. These numbers ↩